2 Geographically Weighted Summary Statistics
2.1 Introduction
In fire management, it is crucial to investigate where fires occurred more frequently and to distinguish between small and large fires. This is key information to understand the ignition factors and planning strategies to reduce forest fires, control and manage ignition sources, and identify areas at risk.
Despite the availability of forest fires spatio-temporal inventories, it is not evident to extract information about their pattern distribution simply by looking at the original arrangement of the mapped burnt areas. To this end, Geographically Weighed Summary Statistics (GWSS) can be computed, under the assumption that burned areas generally follow a geographic trend.
We compute here the GW local means, the GW local standard deviation and the GW localized skewness of burned areas in continental Portugal, registered in the period 1990-2013. This application is inspired by the work of1
2.2 The overall methodology
Summary statistics include a number of measures that can be used to summarize a set of observations, the most important of which are measures of central tendency (arithmetic mean, median and mode) and measures of dispersion around the mean (variance and standard deviation). In addition, measures of skewness and kurtosis are descriptors of the shape of the probability distribution function, the former indicating the asymmetry and the latter the peakedness/tailedness of the curve.
In the case of spatial data, these global statistical descriptors may vary from one region to another, as their values may be affected by local environmental and socio-economic factors. In this case, an appropriately localized calibration can provide a better description of the observed values. One way to achieve this goal is to weight the above statistical measures for a given quantitative variable based on their geographical location.
We introduce here the method proposed by2 and implemented in the function GWSS presented in the .3 The evaluation of geographically weighted summary statistics is obtained by computing a summary for a small area around each geolocalized punctual observation, by using the kernel density estimation technique (KDE).4 KDE is estimated at each point, taking into account the influence of the points falling within an area, with increasing weight towards the center, corresponding to the point location. A surface summary statistic is thus obtained.
2.3 Forest fires dataset
Forest fires inventories indicating the location, the starting date and other related variables, such as the cause of ignition and the size of the area burned, are broadly available with a different degree of accuracy in different countries.
In the present study, we consider the Portuguese National Mapping Burnt Areas (NMBA 2016), freely available from the website of the Institute for the Conservation of Nature and Forests (ICNF). This is a long spatio-temporal dataset (from 1975) resulting from the processing of satellite images acquired once a year at the end of the summer season. Row data consist of records of observed fire scars. The burned areas were estimated by using image classification techniques, then compared with ground data to resolve the discrepancies. Polygons have been converted into point shapefile, where each point represent the centroid of the burned areas, while the size of the burned areas and the starting date of the fires events are given as attributes. In this work, for consistency reasons, we consider only fires occurred between 1990 and 2013 and with a burned area above 5 hectares. .
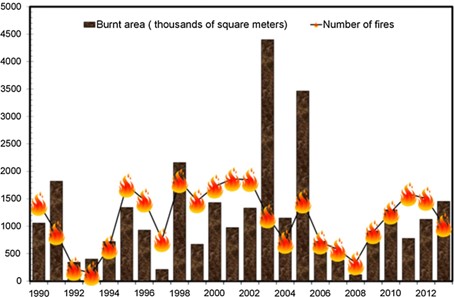
Figure 2.1: Total annual number of forest fire events, expressed in thousands of square metres
2.3.1 Load the libraries
First you have to load the following libraries:
- splancs: for display and analysis of spatial point pattern data
- GWmodel: techniques from a particular branch of spatial statistics, termed geographically-weighted (GW) models
- sf: support for simple features, a standardized way to encode spatial vector data
- ggplot2: a system for ‘declaratively’ creating graphics
- sp: classes and methods for spatial data
#> [1] "ggplot2" "sf" "GWmodel" "Rcpp"
#> [5] "robustbase" "splancs" "sp" "stats"
#> [9] "graphics" "grDevices" "utils" "datasets"
#> [13] "methods" "base"2.3.2 Import the Portuguese forest fire dataset
In this section you will load the geodata representing the dataset of forest fires occurred in the continental Portuguese area in the period 1990-2013. You will also load the boundaries of the study area. You will start by exploring the datasets using mainly visual tools (plotting and histogram).
You can explore the dataset by using different tools for exploratory data analyses. You will start by visualizing the databases. In the GIS environment, this correspond to the attribute table of a vector punctual feature.
Than you can plot the histogram of events distribution based on the variable “Area_ha” (the size in hectares of the burned area). Since this is a power low distribution, for a better understanding it’s recommended to transform the data using a logarithmic scale. Using Log10 you can easily evaluate the frequency distribution of the burned areas.
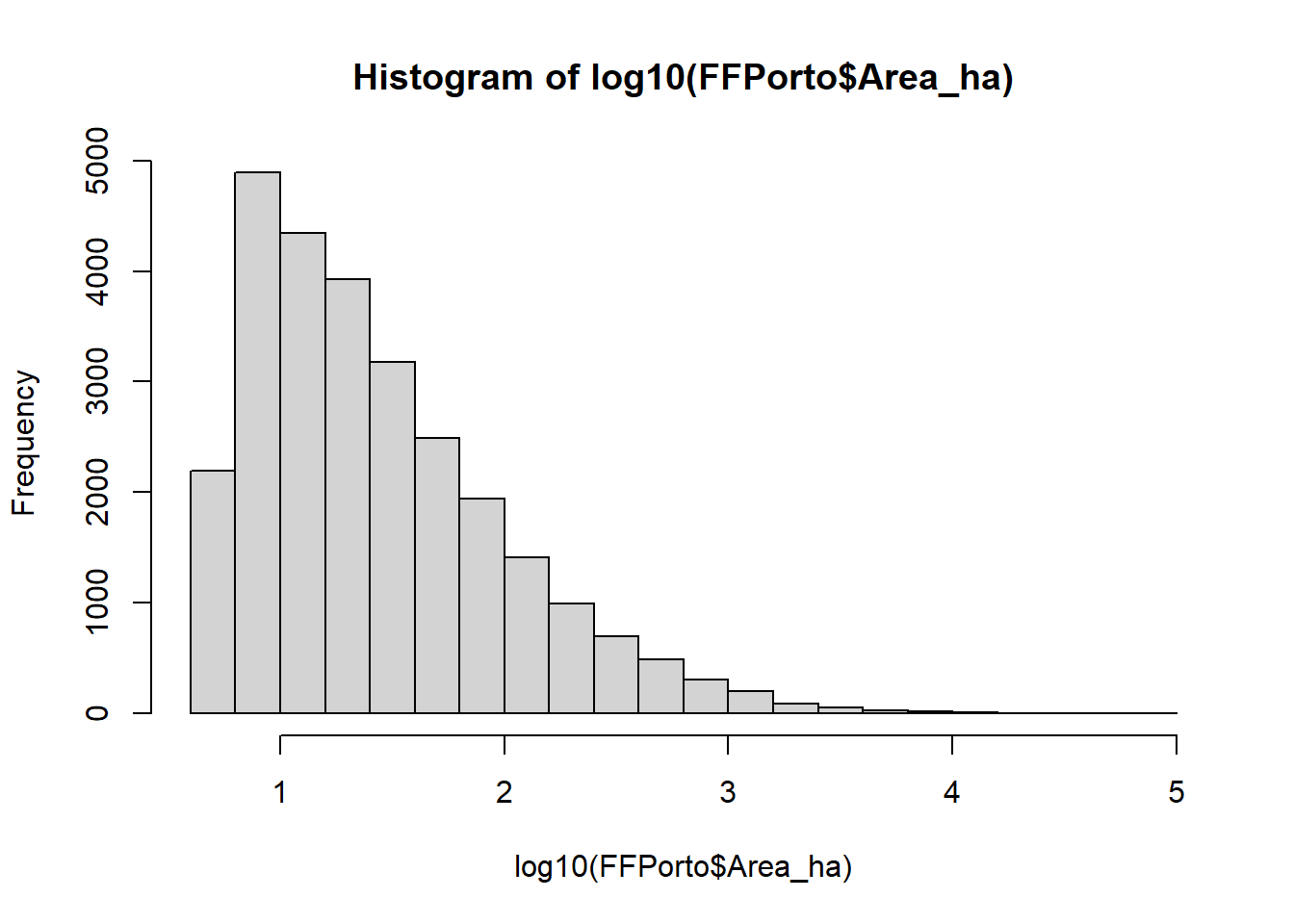
2.3.3 Forest fires spatial distribution
For a better understanding of the phenomenon, you can group the events according to the size of the burned area. Based on the frequency distribution of the burned areas, the following three classes can be defined:
Small fires: less than 15 ha
Medium fires: between 15 ha and 100 ha
Large fires: bigger than 100 ha
Plotting the forest fires events using different colors, based on the size of the burned areas, can simplify the understanding of their pattern distribution, knowing that fires of different size have normally different drivers.
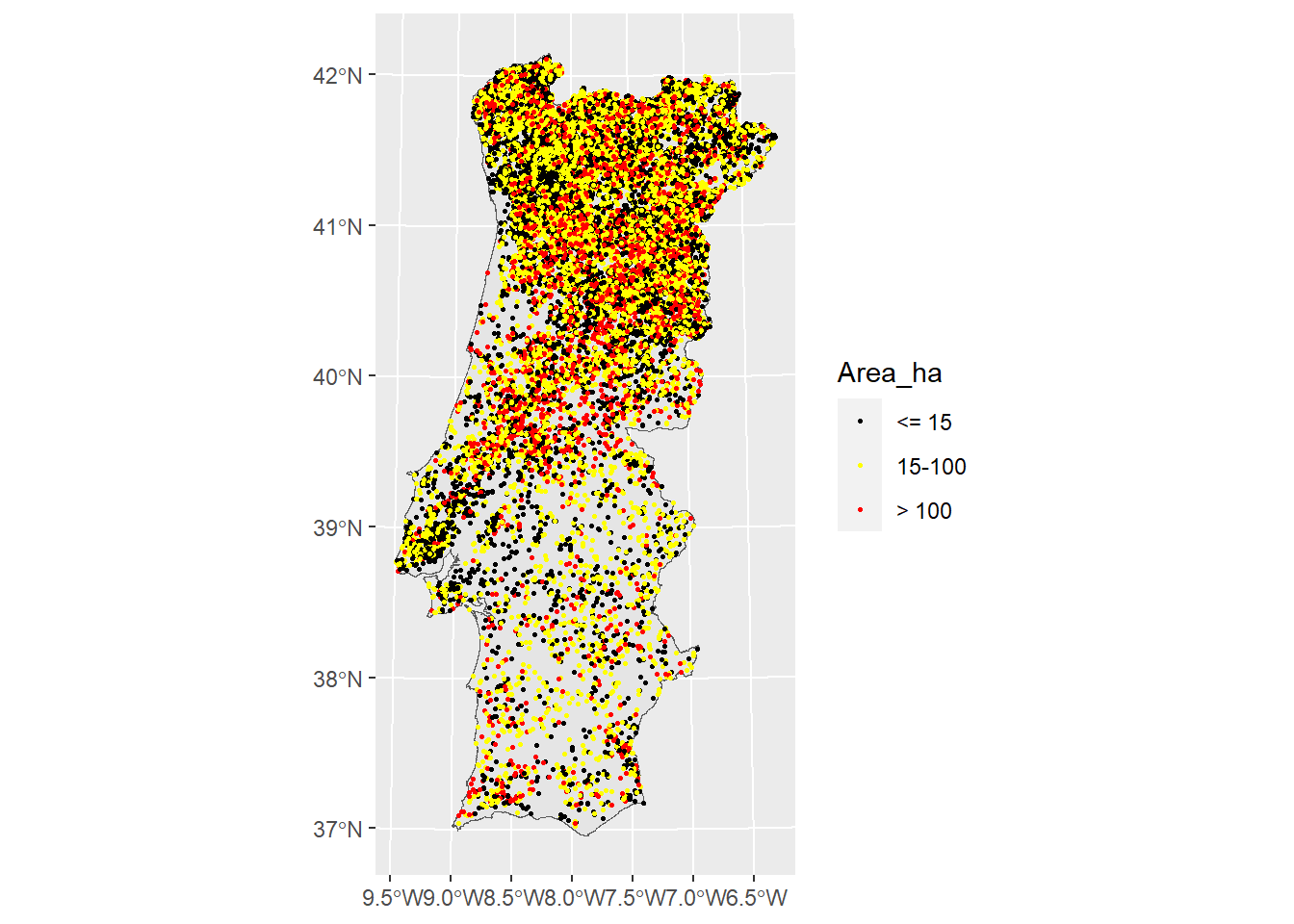
2.4 Compute the geographically whited statistics
From the exploratory data analysis performed above, it seems that a simple plotting of the forest fires events based on their spatial distribution, even if classified based on their size, can not really help to understand their behaviors. This is because we face to a huge number of events and the variable that we are using to characterize them (i.e., the size of the burned area) is very heterogeneous. To this aim, we can compute basic and robust GWSS and plot the data accordingly.
GWSS includes geographically weighted means, standard deviations and the skweness. As you can see from the R Documentation (command: , same data manipulations are necessary to transform the forest fires dataset in a compatible data frame format.
GWSS parameters:
We summarize the data based on the size of the burned area (vars).
We use here an adaptive kernel where the bandwidth (bw) corresponds to the number (100 in this case) of nearest neighbors (i.e. adaptive distance).
We keep the default values for the other parameters.
2.4.1 Look at the results
The resulting object (FFgwss) has a number of components. The most important one is the spatial data frame containing the results of local summary statistics for each data point location, stored in FFgwss$SDF (that is a spatial DataFrame).
2.4.2 GWSS maps
To produce a map of the local geographically weighted summary statistic of your choice, firstly we need to enter a small R function definition. This is just a short R program to draw a map: you can think of it as a command that tells R how to draw a map (see Geographically Weighted Summary Statistics (https://rpubs.com/chrisbrunsdon/99667) for more details). The advantage of defining a function is that the entire map can now be drawn using a single command for each variable, rather than having to repeat those steps each time. To define the intervals for the classification we used Jenks natural breaks classification method (textcolor{red}{style=“fisher”}).
Finally the function is called by entering:
quick.map(gwss.object,variable.name,legend.title,main.map.title)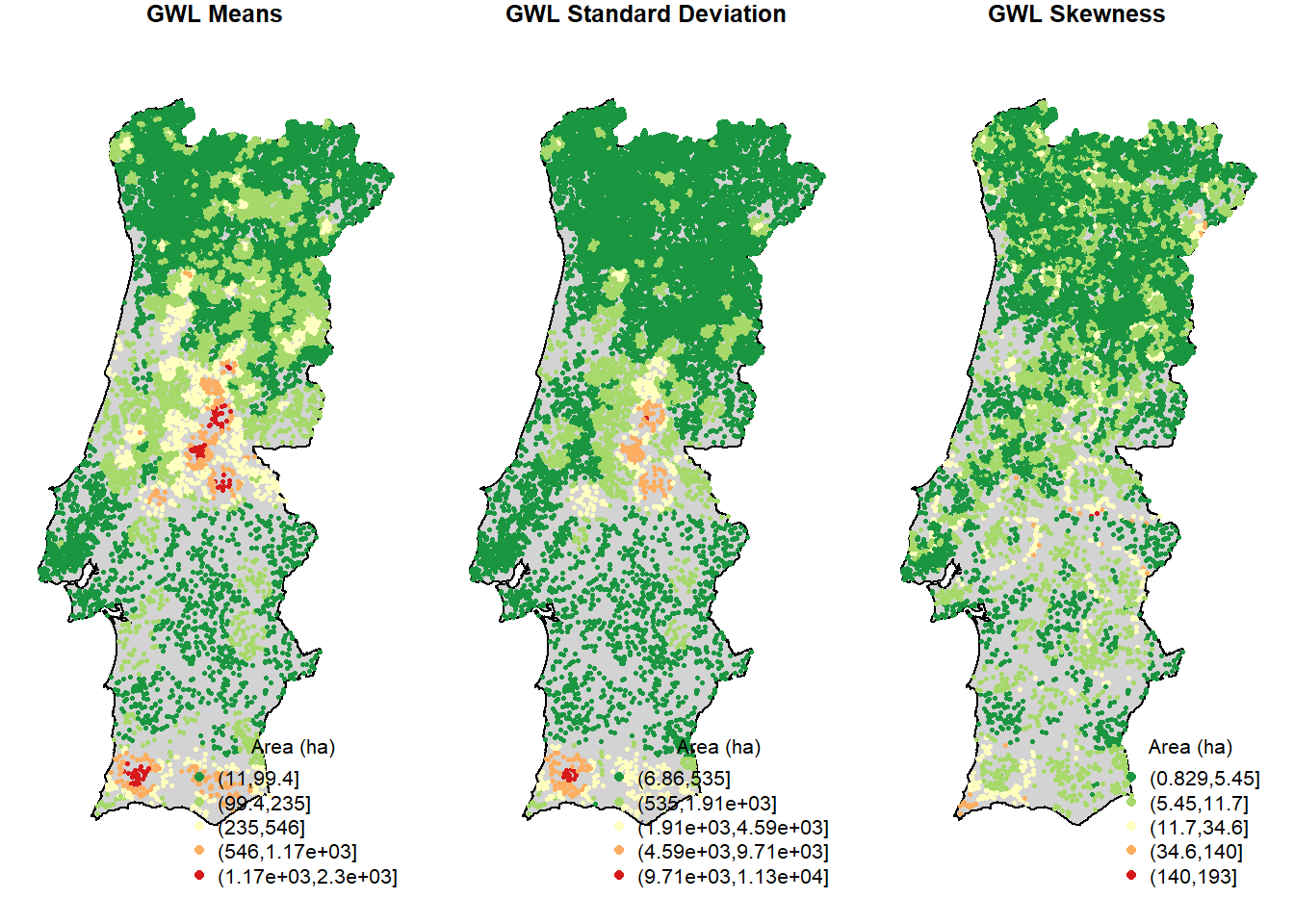
2.5 Conclusions and further analyses
This practical computer lab allowed you to familiarize with GWSS, by the proposed application about geographically weighted summary statistics. This method allowed us to explore how the average burned area vary locally through Continental Portugal in the period 1990-2013.
The global Geographically Weighted (GW) means informs you about the local average value of the burned area, based of the neighboring events occurred in a given period. Similarly, you may compute a GW standard deviation to see the extent to which the size of the burned area spread around this mean. Finally you can compute the GW skewness to measure the symmetry of distribution: a positively skewed distribution means that there is a higher number of data points having low values, with mean value lower that the median; and the contrary for a negatively skewed distribution.
To be sure that everything is perfectly clear for you, we propose you to answer the following questions and to discuss your answers with the other participants to the course or directly with the teacher.
What is the pattern distribution of the GW-means for burned area in Portugal during the investigated periods?
Does the GW-standard deviation follows the same pattern? How can you interpret the two pattern in terms of burned area and their characterization?
GW-skewness has positive values everywhere: what does it means? What do these values suggest to be the distribution of the burned areas, in terms of their size, around the local means?
Which can be other applications of GWSS for geo-environmental data? In other words, can you imagine other geo-environmental dataset that can be analysed using GWSS?
-
You can finally play with the code and try to run it using a different numbers of nearest neighbors (bw=x) and comparing the results.
NB: You have to rename the original pdf to avoid overwriting it. In addition, if a pdf with the same name saved in the same destination folder is open, you will receive an error message, so close it before Knitting.